In this tutorial, we’ll learn about doing standard natural language processing (NLP) tasks in R, and will be introduced to regular expressions. After completing this notebook, you should be familar with:
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(quanteda)
Package version: 4.0.2
Unicode version: 14.0
ICU version: 71.1
Parallel computing: disabled
See https://quanteda.io for tutorials and examples.
Annotators: udpipe, spacy, and CoreNLP
The standard-bearer for NLP work is Stanford’s CoreNLP suite (available here). Historically, that work was available in Java, with really ineffective ports to other programming languages. Fortunately, the past few years have seen major progress in making the suite more accessible in both Python and R. We’re going to leverage the best package with the best port to R — cleanNLP — for our NLP tasks.
Stanford’s CoreNLP, though, is just one of many NLP annotation tools available with cleanNLP. There are two important points to highlight related to this. First, in addition to CoreNLP, cleanNLP can leverage spacy, a high-powered Python library; spacy is (much) faster than CoreNLP, but with some cost in classification accuracy. Second, both CoreNLP and spacy require a Python installation on your machine. Because of that, we can’t run the CoreNLP or spacy code in R (it’s a long story). We will be able to use the universal dependencies pipe (udpipe), so that’s what we’ll do here.
More generally, though, you’ll want to have the capacity provided by CoreNLP or spacy available for your projects on your personal machine. Therefore, you need to install Python. I recommend installing Anaconda Python (available here). Once you’ve done that, you’ll need to install the cleanNLP module within Python.
NLP in R with cleanNLP
To get started, you’ll need to initialize the NLP backend. We’ll be using the udpipe backend, which comes installed with the cleanNLP package.
cnlp_init_udpipe()
We have our NLP backend initialized and ready to roll. We’ll be using the U.S. Presidential Inaugural Address corpus, which comes pre-loaded with quanteda. The corpus is already in your workspace (since it is pre-loaded) as data_corpus_inaugural; it features speeches from 1789 to the present, with document variables indicating the year (Year) of the speech, the last name of the president (President), and their political party (Party).
# pull the corpus as a character vector (which works with cleanNLP) rather than a corpus object, which does not.text <-as.character(data_corpus_inaugural)# To give you an idea of what these look like, here's Biden's speechtext[length(text)]
2021-Biden
"Chief Justice Roberts, Vice President Harris, Speaker Pelosi, Leader Schumer, Leader McConnell, Vice President Pence, distinguished guests, and my fellow Americans.\n\nThis is America's day.\n\nThis is democracy's day.\n\nA day of history and hope.\n\nOf renewal and resolve.\n\nThrough a crucible for the ages America has been tested anew and America has risen to the challenge.\n\nToday, we celebrate the triumph not of a candidate, but of a cause, the cause of democracy.\n\nThe will of the people has been heard and the will of the people has been heeded.\n\nWe have learned again that democracy is precious.\n\nDemocracy is fragile.\n\nAnd at this hour, my friends, democracy has prevailed.\n\nSo now, on this hallowed ground where just days ago violence sought to shake this Capitol's very foundation, we come together as one nation, under God, indivisible, to carry out the peaceful transfer of power as we have for more than two centuries.\n\nWe look ahead in our uniquely American way – restless, bold, optimistic – and set our sights on the nation we know we can be and we must be.\n\nI thank my predecessors of both parties for their presence here.\n\nI thank them from the bottom of my heart.\n\nYou know the resilience of our Constitution and the strength of our nation.\n\nAs does President Carter, who I spoke to last night but who cannot be with us today, but whom we salute for his lifetime of service.\n\nI have just taken the sacred oath each of these patriots took — an oath first sworn by George Washington.\n\nBut the American story depends not on any one of us, not on some of us, but on all of us.\n\nOn \"We the People\" who seek a more perfect Union.\n\nThis is a great nation and we are a good people.\n\nOver the centuries through storm and strife, in peace and in war, we have come so far. But we still have far to go.\n\nWe will press forward with speed and urgency, for we have much to do in this winter of peril and possibility.\n\nMuch to repair.\n\nMuch to restore.\n\nMuch to heal.\n\nMuch to build.\n\nAnd much to gain.\n\nFew periods in our nation's history have been more challenging or difficult than the one we're in now.\n\nA once-in-a-century virus silently stalks the country.\n\nIt's taken as many lives in one year as America lost in all of World War II.\n\nMillions of jobs have been lost.\n\nHundreds of thousands of businesses closed.\n\nA cry for racial justice some 400 years in the making moves us. The dream of justice for all will be deferred no longer.\n\nA cry for survival comes from the planet itself. A cry that can't be any more desperate or any more clear.\n\nAnd now, a rise in political extremism, white supremacy, domestic terrorism that we must confront and we will defeat.\n\nTo overcome these challenges – to restore the soul and to secure the future of America – requires more than words.\n\nIt requires that most elusive of things in a democracy:\n\nUnity.\n\nUnity.\n\nIn another January in Washington, on New Year's Day 1863, Abraham Lincoln signed the Emancipation Proclamation.\n\nWhen he put pen to paper, the President said, \"If my name ever goes down into history it will be for this act and my whole soul is in it.\"\n\nMy whole soul is in it.\n\nToday, on this January day, my whole soul is in this:\n\nBringing America together.\n\nUniting our people.\n\nAnd uniting our nation.\n\nI ask every American to join me in this cause.\n\nUniting to fight the common foes we face:\n\nAnger, resentment, hatred.\n\nExtremism, lawlessness, violence.\n\nDisease, joblessness, hopelessness.\n\nWith unity we can do great things. Important things.\n\nWe can right wrongs.\n\nWe can put people to work in good jobs.\n\nWe can teach our children in safe schools.\n\nWe can overcome this deadly virus.\n\nWe can reward work, rebuild the middle class, and make health care\n\nsecure for all.\n\nWe can deliver racial justice.\n\nWe can make America, once again, the leading force for good in the world.\n\nI know speaking of unity can sound to some like a foolish fantasy.\n\nI know the forces that divide us are deep and they are real.\n\nBut I also know they are not new.\n\nOur history has been a constant struggle between the American ideal that we are all created equal and the harsh, ugly reality that racism, nativism, fear, and demonization have long torn us apart.\n\nThe battle is perennial.\n\nVictory is never assured.\n\nThrough the Civil War, the Great Depression, World War, 9/11, through struggle, sacrifice, and setbacks, our \"better angels\" have always prevailed.\n\nIn each of these moments, enough of us came together to carry all of us forward.\n\nAnd, we can do so now.\n\nHistory, faith, and reason show the way, the way of unity.\n\nWe can see each other not as adversaries but as neighbors.\n\nWe can treat each other with dignity and respect.\n\nWe can join forces, stop the shouting, and lower the temperature.\n\nFor without unity, there is no peace, only bitterness and fury.\n\nNo progress, only exhausting outrage.\n\nNo nation, only a state of chaos.\n\nThis is our historic moment of crisis and challenge, and unity is the path forward.\n\nAnd, we must meet this moment as the United States of America.\n\nIf we do that, I guarantee you, we will not fail.\n\nWe have never, ever, ever failed in America when we have acted together.\n\nAnd so today, at this time and in this place, let us start afresh.\n\nAll of us.\n\nLet us listen to one another.\n\nHear one another.\n\nSee one another.\n\nShow respect to one another.\n\nPolitics need not be a raging fire destroying everything in its path.\n\nEvery disagreement doesn't have to be a cause for total war.\n\nAnd, we must reject a culture in which facts themselves are manipulated and even manufactured.\n\nMy fellow Americans, we have to be different than this.\n\nAmerica has to be better than this.\n\nAnd, I believe America is better than this.\n\nJust look around.\n\nHere we stand, in the shadow of a Capitol dome that was completed amid the Civil War, when the Union itself hung in the balance.\n\nYet we endured and we prevailed.\n\nHere we stand looking out to the great Mall where Dr. King spoke of his dream.\n\nHere we stand, where 108 years ago at another inaugural, thousands of protestors tried to block brave women from marching for the right to vote.\n\nToday, we mark the swearing-in of the first woman in American history elected to national office – Vice President Kamala Harris.\n\nDon't tell me things can't change.\n\nHere we stand across the Potomac from Arlington National Cemetery, where heroes who gave the last full measure of devotion rest in eternal peace.\n\nAnd here we stand, just days after a riotous mob thought they could use violence to silence the will of the people, to stop the work of our democracy, and to drive us from this sacred ground.\n\nThat did not happen.\n\nIt will never happen.\n\nNot today.\n\nNot tomorrow.\n\nNot ever.\n\nTo all those who supported our campaign I am humbled by the faith you have placed in us.\n\nTo all those who did not support us, let me say this: Hear me out as we move forward. Take a measure of me and my heart.\n\nAnd if you still disagree, so be it.\n\nThat's democracy. That's America. The right to dissent peaceably, within the guardrails of our Republic, is perhaps our nation's greatest strength.\n\nYet hear me clearly: Disagreement must not lead to disunion.\n\nAnd I pledge this to you: I will be a President for all Americans.\n\nI will fight as hard for those who did not support me as for those who did.\n\nMany centuries ago, Saint Augustine, a saint of my church, wrote that a people was a multitude defined by the common objects of their love.\n\nWhat are the common objects we love that define us as Americans?\n\nI think I know.\n\nOpportunity.\n\nSecurity.\n\nLiberty.\n\nDignity.\n\nRespect.\n\nHonor.\n\nAnd, yes, the truth.\n\nRecent weeks and months have taught us a painful lesson.\n\nThere is truth and there are lies.\n\nLies told for power and for profit.\n\nAnd each of us has a duty and responsibility, as citizens, as Americans, and especially as leaders – leaders who have pledged to honor our Constitution and protect our nation — to defend the truth and to defeat the lies.\n\nI understand that many Americans view the future with some fear and trepidation.\n\nI understand they worry about their jobs, about taking care of their families, about what comes next.\n\nI get it.\n\nBut the answer is not to turn inward, to retreat into competing factions, distrusting those who don't look like you do, or worship the way you do, or don't get their news from the same sources you do.\n\nWe must end this uncivil war that pits red against blue, rural versus urban, conservative versus liberal.\n\nWe can do this if we open our souls instead of hardening our hearts.\n\nIf we show a little tolerance and humility.\n\nIf we're willing to stand in the other person's shoes just for a moment.\n\nBecause here is the thing about life: There is no accounting for what fate will deal you.\n\nThere are some days when we need a hand.\n\nThere are other days when we're called on to lend one.\n\nThat is how we must be with one another.\n\nAnd, if we are this way, our country will be stronger, more prosperous, more ready for the future.\n\nMy fellow Americans, in the work ahead of us, we will need each other.\n\nWe will need all our strength to persevere through this dark winter.\n\nWe are entering what may well be the toughest and deadliest period of the virus.\n\nWe must set aside the politics and finally face this pandemic as one nation.\n\nI promise you this: as the Bible says weeping may endure for a night but joy cometh in the morning.\n\nWe will get through this, together\n\nThe world is watching today.\n\nSo here is my message to those beyond our borders: America has been tested and we have come out stronger for it.\n\nWe will repair our alliances and engage with the world once again.\n\nNot to meet yesterday's challenges, but today's and tomorrow's.\n\nWe will lead not merely by the example of our power but by the power of our example.\n\nWe will be a strong and trusted partner for peace, progress, and security.\n\nWe have been through so much in this nation.\n\nAnd, in my first act as President, I would like to ask you to join me in a moment of silent prayer to remember all those we lost this past year to the pandemic.\n\nTo those 400,000 fellow Americans – mothers and fathers, husbands and wives, sons and daughters, friends, neighbors, and co-workers.\n\nWe will honor them by becoming the people and nation we know we can and should be.\n\nLet us say a silent prayer for those who lost their lives, for those they left behind, and for our country.\n\nAmen.\n\nThis is a time of testing.\n\nWe face an attack on democracy and on truth.\n\nA raging virus.\n\nGrowing inequity.\n\nThe sting of systemic racism.\n\nA climate in crisis.\n\nAmerica's role in the world.\n\nAny one of these would be enough to challenge us in profound ways.\n\nBut the fact is we face them all at once, presenting this nation with the gravest of responsibilities.\n\nNow we must step up.\n\nAll of us.\n\nIt is a time for boldness, for there is so much to do.\n\nAnd, this is certain.\n\nWe will be judged, you and I, for how we resolve the cascading crises of our era.\n\nWill we rise to the occasion?\n\nWill we master this rare and difficult hour?\n\nWill we meet our obligations and pass along a new and better world for our children?\n\nI believe we must and I believe we will.\n\nAnd when we do, we will write the next chapter in the American story.\n\nIt's a story that might sound something like a song that means a lot to me.\n\nIt's called \"American Anthem\" and there is one verse stands out for me:\n\n\"The work and prayers\n\nof centuries have brought us to this day\n\nWhat shall be our legacy?\n\nWhat will our children say?…\n\nLet me know in my heart\n\nWhen my days are through\n\nAmerica\n\nAmerica\n\nI gave my best to you.\"\n\nLet us add our own work and prayers to the unfolding story of our nation.\n\nIf we do this then when our days are through our children and our children's children will say of us they gave their best.\n\nThey did their duty.\n\nThey healed a broken land.\n\nMy fellow Americans, I close today where I began, with a sacred oath.\n\nBefore God and all of you I give you my word.\n\nI will always level with you.\n\nI will defend the Constitution.\n\nI will defend our democracy.\n\nI will defend America.\n\nI will give my all in your service thinking not of power, but of possibilities.\n\nNot of personal interest, but of the public good.\n\nAnd together, we shall write an American story of hope, not fear.\n\nOf unity, not division.\n\nOf light, not darkness.\n\nAn American story of decency and dignity.\n\nOf love and of healing.\n\nOf greatness and of goodness.\n\nMay this be the story that guides us.\n\nThe story that inspires us.\n\nThe story that tells ages yet to come that we answered the call of history.\n\nWe met the moment.\n\nThat democracy and hope, truth and justice, did not die on our watch but thrived.\n\nThat our America secured liberty at home and stood once again as a beacon to the world.\n\nThat is what we owe our forebearers, one another, and generations to follow.\n\nSo, with purpose and resolve we turn to the tasks of our time.\n\nSustained by faith.\n\nDriven by conviction.\n\nAnd, devoted to one another and to this country we love with all our hearts.\n\nMay God bless America and may God protect our troops.\n\nThank you, America."
# pull out the data we wantmyData <-docvars(data_corpus_inaugural)head(myData)
Year President FirstName Party
1 1789 Washington George none
2 1793 Washington George none
3 1797 Adams John Federalist
4 1801 Jefferson Thomas Democratic-Republican
5 1805 Jefferson Thomas Democratic-Republican
6 1809 Madison James Democratic-Republican
tail(myData)
Year President FirstName Party
54 2001 Bush George W. Republican
55 2005 Bush George W. Republican
56 2009 Obama Barack Democratic
57 2013 Obama Barack Democratic
58 2017 Trump Donald J. Republican
59 2021 Biden Joseph R. Democratic
# now add the text to our data frame for running the annotation tool; column must be named `text`myData$text <- text
The steps we take in the above get the data ready for use with the NLP package cleanNLP. This is, unfortunately, a common theme in R and other open-source programming languages. The ability for users to contribute their own packages means we have an enormous amount of flexibility and progress happens fast, but the trade off is that the different packages don’t always play well with one another. As you get more familiar with working in R, getting used to moving between the preferred formats of different packages becomes easier.
With that said, those simple steps above are all we need to do to get our texts ready for annotation with cleanNLP, which takes a vector of file names, a character vector with one document in each element, or a data frame as input. If we have a corpus — as we often do — we can convert it to a character vector as above and be ready to annotate.
Annotation: cnlp_annotate()
So, let’s annotate. The next line is going to take a few minutes so it’s a good chance to go take care of making that pot of coffee you forgot to make before starting this up.
annotated <-cnlp_annotate(myData)
Processed document 10 of 59
Processed document 20 of 59
Processed document 30 of 59
Processed document 40 of 59
Processed document 50 of 59
The output for each of the backends is going to look a little bit different, though the general structure will be consistent. Here we can start seeing what our udpipe annotation looks like. The first thing to note is that it is a very particular type of object with two fields: token and document. Both are dataframes; token is a dataframe featuring the annotations from the text, while document is a dataframe featuring just the unique document IDs. We’ll primarily be interested in the former.
head(annotated$token)
# A tibble: 6 × 11
doc_id sid tid token token_with_ws lemma upos xpos feats tid_source
<int> <int> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 1 1 1 Fellow "Fellow" fellow ADJ JJ Degr… 3
2 1 1 2 - "-" - PUNCT HYPH <NA> 3
3 1 1 3 Citizens "Citizens " citizen NOUN NNS Numb… 0
4 1 1 4 of "of " of ADP IN <NA> 6
5 1 1 5 the "the " the DET DT Defi… 6
6 1 1 6 Senate "Senate " Senate PROPN NNP Numb… 3
# ℹ 1 more variable: relation <chr>
If we wanted, we could create a single database from both of these using doc_id variable present in both. This is particularly helpful for downstream analyses we might want to do that would analyze — say — patterns over time.
annoData <-left_join(annotated$document, annotated$token, by ="doc_id")head(annoData)
Year President FirstName Party doc_id sid tid token token_with_ws lemma
1 1789 Washington George none 1 1 1 Fellow Fellow fellow
2 1789 Washington George none 1 1 2 - - -
3 1789 Washington George none 1 1 3 Citizens Citizens citizen
4 1789 Washington George none 1 1 4 of of of
5 1789 Washington George none 1 1 5 the the the
6 1789 Washington George none 1 1 6 Senate Senate Senate
upos xpos feats tid_source relation
1 ADJ JJ Degree=Pos 3 amod
2 PUNCT HYPH <NA> 3 punct
3 NOUN NNS Number=Plur 0 root
4 ADP IN <NA> 6 case
5 DET DT Definite=Def|PronType=Art 6 det
6 PROPN NNP Number=Sing 3 nmod
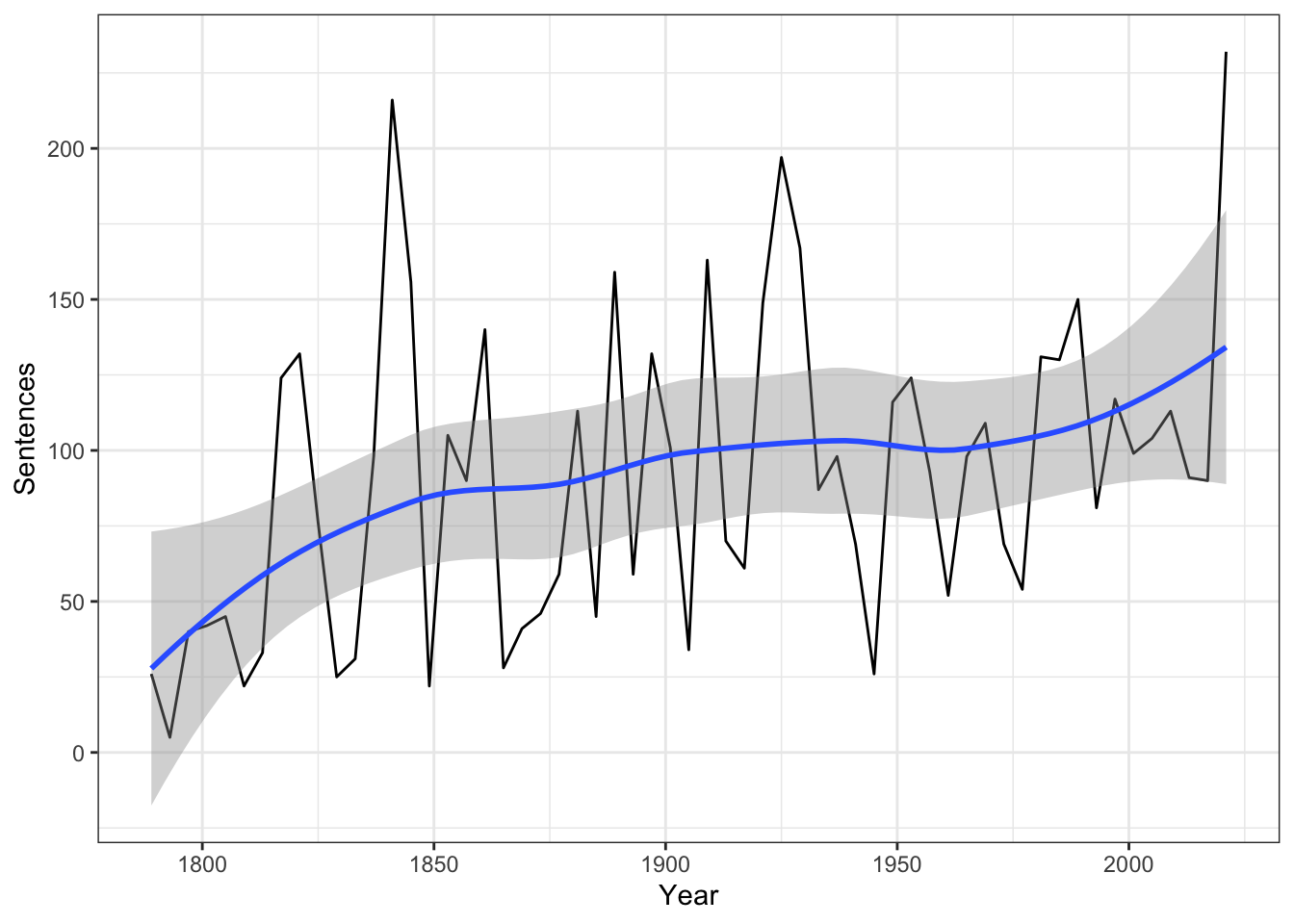
Let’s discuss what this new annotated data set provides. First, note that speeches are now organized at the token level. Three variables help us to index this new level: doc_id, the number of the document in the corpus; sid, the number of the sentence within the document; and tid, the number of the token within the sentence. At a really basic level then, we can now figure out the number of sentences within each document, and the average length (in tokens) of those sentences. Here’s the former.
# plot length of documents (in sentences) over timeannoData %>%group_by(Year) %>%summarize(Sentences =max(sid)) %>%ggplot(aes(Year, Sentences)) +geom_line() +geom_smooth() +theme_bw()
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
That said, the real prize of the annotations are the details related to each individual token. The next three columns (token, token_with_ws, and lemma) all relate directly to the actual characters of the token. Take, as an example, “Citizens” (third row). The token is “Citizens”, while the lemma is a headword for a group of related words; here, “citizen” is the lemma of “Citizens” as it is the non-plural version of the token. To get an idea of how else lemmatization changes the tokens, here’s a comparison of the first 40 tokens in the dataset.
Lemmatization can be particularly useful as a pre-processing step in some analyses; topic modeling immediately comes to mind. The general reason is that references to different forms of the same underlying token (say, “transmit”, “transmitted”, “transmits”) all connote one related concept but are going to be treated as entirely distinct tokens if we were to say just look for the most frequent tokens in the corpus or in a speech. We’ll come back to this later this semester when we discuss stemming and other related pre-processing considerations.
Part of Speech Tagging
Now we are into the heart of the annotations. Let’s highlight a chunk of the data to use as illustrations.
# First tokens from Trump's speechhead(annoData[which(annoData$Year ==2017),9:15],28)
token_with_ws lemma upos xpos feats
147953 Chief Chief PROPN NNP Number=Sing
147954 Justice Justice PROPN NNP Number=Sing
147955 Roberts Roberts PROPN NNP Number=Sing
147956 , , PUNCT , <NA>
147957 President President PROPN NNP Number=Sing
147958 Carter Carter PROPN NNP Number=Sing
147959 , , PUNCT , <NA>
147960 President President PROPN NNP Number=Sing
147961 Clinton Clinton PROPN NNP Number=Sing
147962 , , PUNCT , <NA>
147963 President President PROPN NNP Number=Sing
147964 Bush Bush PROPN NNP Number=Sing
147965 , , PUNCT , <NA>
147966 President President PROPN NNP Number=Sing
147967 Obama Obama PROPN NNP Number=Sing
147968 , , PUNCT , <NA>
147969 fellow fellow ADJ JJ Degree=Pos
147970 Americans Americans PROPN NNPS Number=Plur
147971 , , PUNCT , <NA>
147972 and and CCONJ CC <NA>
147973 people people NOUN NNS Number=Plur
147974 of of ADP IN <NA>
147975 the the DET DT Definite=Def|PronType=Art
147976 world world NOUN NN Number=Sing
147977 : : PUNCT : <NA>
147978 thank thank VERB VBP Mood=Ind|Tense=Pres|VerbForm=Fin
147979 you you PRON PRP Case=Acc|Person=2|PronType=Prs
147980 .\n\n . PUNCT . <NA>
tid_source relation
147953 2 compound
147954 0 root
147955 2 flat
147956 2 punct
147957 2 conj
147958 5 flat
147959 8 punct
147960 2 conj
147961 8 flat
147962 11 punct
147963 2 conj
147964 11 flat
147965 14 punct
147966 2 conj
147967 14 flat
147968 18 punct
147969 18 amod
147970 2 conj
147971 21 punct
147972 21 cc
147973 2 conj
147974 24 case
147975 24 det
147976 21 nmod
147977 2 punct
147978 2 parataxis
147979 26 obj
147980 2 punct
Next, upos stands for the universal part of speech tag while xpos stands for the treebank-specific part of speech. You can find descriptions of each upos classification tag here. Knowing the parts of speech, we could — at a really basic level — just look to see what nouns are most frequently used in presidential addresses overall, and in the most recent era (i.e., post 2000).
# A tibble: 10 × 2
lemma count
<chr> <int>
1 freedom 61
2 nation 53
3 people 51
4 world 51
5 time 48
6 government 47
7 country 36
8 day 34
9 citizen 33
10 life 30
# A tibble: 12 × 2
lemma count
<chr> <int>
1 nation 57
2 world 51
3 people 50
4 time 41
5 today 37
6 century 27
7 child 26
8 life 24
9 government 22
10 day 21
11 democracy 21
12 generation 21
You can further distinguish parts of speech using the feats field, which references more specific “features” related to the parts of speech. More information on the features can be found here.
Dependency Relations
Finally, the relationships between tokens are captured in dependency relations, which are reflected by syntactic annotations through tid_source and relation. The goal of dependency relations is to form a generalizable structure of language that works across languages (thus, universal dependencies). If we want to capture meaning from many different texts in different languages (with all of the different customs of those particular languages), we would first want to have some generalizable structure about how words in languages fit together.
Consider a sentence like: The child chased the dog down the hall. The underlying idea behind dependency relations is to focus primarily on content words; in the above, that would be “child”, “chased”, “dog”, and “hall”. We can start to see how knowing just those four words gets us a long way to understanding what might be happening; if we can add in some sort of structure (say, that “child” is the nominal subject [nsubj], or the do-er of the action, and “dog” is the object [obj], or the receiver of the action) then we can recognize that a child chased a dog (rather than the much-less-cute reverse).
The full list of dependency relations and their abbreviations can be found here.
What can we do with dependency relations? At the simplest level, they can be features that we rely on for classification. For that matter, everything we’ve covered in this tutorial could be a feature. We’ll cover classifiers later this semester and will be able to explore this avenue a bit more then.
We could also, however, be more directly interested in using the dependency relations to study particular choices over word usage in texts. As an example, consider unique phrasings from President Trump’s 2017 speech and President Biden’s 2021 speech (for more on the approach here, see the cleanNLP documentation here.
library(magrittr)
Attaching package: 'magrittr'
The following object is masked from 'package:purrr':
set_names
The following object is masked from 'package:tidyr':
extract
By applying a similar method, we can investigate how adjectives describing “economy” differ in speeches by Democratic and Republican politicians. This allows us to analyze whether the two parties emphasize distinct characteristics of the same topic, potentially reflecting ideological differences.
# DemocraticannoData %>%left_join( annotated$token,c("doc_id"="doc_id", "sid"="sid", "tid"="tid_source"),suffix =c("", "_source") ) %>%filter(Party =="Democratic") %>%filter(lemma =="economy") %>%# Filter for adjectives (ADJ) modifying 'economy' via 'amod' relationfilter(relation_source =="amod"& upos_source =="ADJ") %>%# Select relevant columns: doc_id, the noun ('economy'), and the adjectiveselect(doc_id = doc_id, noun = token, adj = token_source)
Visualizing dependency trees can help us better understand the syntactic structure of sentences and how different words relate to each other. Dependency trees show which words are the “head” of a phrase and which words are dependents, along with the types of relationships (like subject, object, etc.) between them.
library(udpipe)library(rsyntax)
Attaching package: 'rsyntax'
The following objects are masked from 'package:tidyr':
chop, fill
The following object is masked from 'package:ggplot2':
annotate
Now we can annotate text and visualize the dependency tree
text1 <-"Barack Obama was the 44th President of the United States."text2 <-"BAGHDAD. Iraqi leaders criticized Turkey on Monday for bombing Kurdish militants in northern Iraq with airstrikes that they said had left at least one woman dead."tokens1 <-udpipe(text1,'english')tokens2 <-udpipe(text2,'english')#rsyntax requires the tokens to be in a certain format. The as_tokenindex() function converts a data.frame to this format. tokens1 <-as_tokenindex(tokens1)tokens2 <-as_tokenindex(tokens2)#Visualizationplot_tree(tokens1, token, lemma, upos)
Document: doc1
Sentence: 1
plot_tree(tokens2, token, lemma, upos)
Document: doc1
Sentence: 1
Note that this function only prints one sentence a time, so if the sentence is not specified it uses the first sentence in the data.
Named Entity Recognition (NER) is a key task in natural language processing (NLP) that involves identifying and categorizing entities in text, such as people, organizations, locations, dates, and more. While tools like udpipe excel in tasks like part-of-speech tagging and dependency parsing, they are limited in their ability to perform NER. Udpipe models do not consistently include NER capabilities, making them less suited for entity recognition tasks.
In contrast, spacy is a more robust option for NER. It provides high-performance models specifically designed for recognizing named entities in text. Spacy’s NER models can classify entities into a variety of categories, such as PERSON, ORG (organization), and LOC (location), making it an excellent tool for tasks that require precise entity extraction. Switching to spacy for NER ensures more accurate and reliable results, especially when working with real-world text data.
Remember we mentioned at the beginning of the tutorial, spacy requires a Python environment. Make sure you have Python installed on your device, and run pip install cleannlp in your terminal or Python to install the cleannlp Python module.
# Download the spacy model# cnlp_download_spacy("en_core_web_sm")# Initialize spacy backendcnlp_init_spacy()
Now we start with some easy tasks:
text1
[1] "Barack Obama was the 44th President of the United States."
# A tibble: 3 × 6
doc_id sid tid tid_end entity_type entity
<int> <int> <int> <int> <chr> <chr>
1 1 1 1 2 PERSON Barack Obama
2 1 1 5 5 ORDINAL 44th
3 1 1 8 10 GPE the United States
text2
[1] "BAGHDAD. Iraqi leaders criticized Turkey on Monday for bombing Kurdish militants in northern Iraq with airstrikes that they said had left at least one woman dead."
Now let’s look into the top person mentioned by the Democratic and Republican Party
annotated_spacy <-cnlp_annotate(myData)
Processed document 10 of 59
Processed document 20 of 59
Processed document 30 of 59
Processed document 40 of 59
Processed document 50 of 59
annoData_spacy <-left_join(annotated_spacy$document, annotated_spacy$entity, by ="doc_id")head(annoData_spacy)
Year President FirstName Party doc_id sid tid tid_end entity_type
1 1789 Washington George none 1 1 1 6 ORG
2 1789 Washington George none 1 1 9 12 ORG
3 1789 Washington George none 1 1 45 47 DATE
4 1789 Washington George none 1 1 49 51 DATE
5 1789 Washington George none 1 2 11 11 ORG
6 1789 Washington George none 1 2 55 55 DATE
entity
1 Fellow-Citizens of the Senate
2 the House of Representatives
3 the 14th day
4 the present month
5 Country
6 years
# A tibble: 17 × 2
entity count
<chr> <int>
1 God 7
2 Chief Justice 6
3 Bush 4
4 Clinton 4
5 Speaker 4
6 Abraham Lincoln 3
7 George Washington 3
8 Jefferson 3
9 Administrations 2
10 Carter 2
11 Dole 2
12 Domingo 2
13 Mathias 2
14 Monroe 2
15 O'Neill 2
16 Thomas Jefferson 2
17 decay 2
String Operations
To this point, we’ve worked on getting our text into R, getting some basic statistics out, and annotating that text. One thing we have skipped past is a really foundational tool in programming, regular expressions. The idea here is to create a pattern of text that we can search for. To see what we can do with regular expressions, let’s start playing with them.
We are going to use the stringr library, which is associated with the tidyverse. To be clear, a lot of what we do could be done in base R, but the language for the base R functions (grep(),gsub()`, etc.) can be far less intuitive.
library(stringr)
What’s in a string?
Let’s look at some simpler data first.
length(sentences)
[1] 720
head(sentences)
[1] "The birch canoe slid on the smooth planks."
[2] "Glue the sheet to the dark blue background."
[3] "It's easy to tell the depth of a well."
[4] "These days a chicken leg is a rare dish."
[5] "Rice is often served in round bowls."
[6] "The juice of lemons makes fine punch."
string <-'It\'s easy to tell the depth of a well.'
As you can see, sentences contains 720 short and simple sentences. We’ll use these to illustrate regular expressions. A first thing to note is the string. See that \? That’s an escape, and tells R to ignore the single quote. Why is this important? Well, notice what demarcates each sentence that’s being printed. That’s right, single quotes! So the \ let’s R know that the element is not yet complete. That doesn’t mean the \ is always there though. If you want to see the “printed” version of the sentence, you can use writeLines()
writeLines(head(sentences))
The birch canoe slid on the smooth planks.
Glue the sheet to the dark blue background.
It's easy to tell the depth of a well.
These days a chicken leg is a rare dish.
Rice is often served in round bowls.
The juice of lemons makes fine punch.
There are lots of other special characters that may require escapes in R if you are doing regular expression matching. That can be particularly challenging because of the special meanings of those special characters — like the single quote — leads to particular operations. As an example, the single period . in a regular expression is a wild card for character matching, and will match any character but a newline. Therefore, if you include the . in a regular expression without escaping it, you’ll end up matching just about everything. The cheat sheet posted to the course website gives more details on these special characters.
Combining strings
Now that we have our strings, let’s do some basic operations. We can combine two strings using the str_c command in stringr. For instance, if we wanted to combine the first two sentences from sentences, we could.
str_c(sentences[1], sentences[2], sep =" ")
[1] "The birch canoe slid on the smooth planks. Glue the sheet to the dark blue background."
This also works if we have two separate string vectors that we’d like to combine. Imagine if we split sentences in half; we could combine the two halves! This is often really helpful if you have a couple of character / string variables in your dataset / metadata that you’d like to combine into a single indicator.
[1] "The birch canoe slid on the smooth planks. Feed the white mouse some flower seeds."
[2] "Glue the sheet to the dark blue background. The thaw came early and freed the stream."
[3] "It's easy to tell the depth of a well. He took the lead and kept it the whole distance."
[4] "These days a chicken leg is a rare dish. The key you designed will fit the lock."
[5] "Rice is often served in round bowls. Plead to the council to free the poor thief."
[6] "The juice of lemons makes fine punch. Better hash is made of rare beef."
You can also combine all of the strings in one vector into a single observation using the collapse option.
length(str_c(head(sentences), collapse =" "))
[1] 1
# Note that the string in collapse is up to you but is what will be pasted # between the elements in the new string. So here's a version with a new line# which gets specified by \nstr_c(head(sentences), collapse ="\n")
[1] "The birch canoe slid on the smooth planks.\nGlue the sheet to the dark blue background.\nIt's easy to tell the depth of a well.\nThese days a chicken leg is a rare dish.\nRice is often served in round bowls.\nThe juice of lemons makes fine punch."
# and here's what that looks like with writeLines() thenwriteLines(str_c(head(sentences), collapse ="\n"))
The birch canoe slid on the smooth planks.
Glue the sheet to the dark blue background.
It's easy to tell the depth of a well.
These days a chicken leg is a rare dish.
Rice is often served in round bowls.
The juice of lemons makes fine punch.
You can also do the opposite, splitting a string into two by using str_split() and identifying a common splitting indicator.
[1] "The birch canoe slid on the smooth planks.\nGlue the sheet to the dark blue background.\nIt's easy to tell the depth of a well.\nThese days a chicken leg is a rare dish.\nRice is often served in round bowls.\nThe juice of lemons makes fine punch."
# create split string; simplify = TRUE returns a matrix (rather than a list)split_string <-str_split(combined_string, "\n", simplify =TRUE)split_string
[,1]
[1,] "The birch canoe slid on the smooth planks."
[,2]
[1,] "Glue the sheet to the dark blue background."
[,3]
[1,] "It's easy to tell the depth of a well."
[,4]
[1,] "These days a chicken leg is a rare dish."
[,5]
[1,] "Rice is often served in round bowls."
[,6]
[1,] "The juice of lemons makes fine punch."
Substrings
Occassionally, we need to pull out parts of strings. For instance, maybe we just want the first few letters of each string. In those instances, we can use str_sub():
# example string this actually makes some sense formonth.name
You can also use str_sub() to change a string through replacement of specific characters. Here we’ll replace the first few letters of every month with “Cat”.
Where regular expressions really kick in isn’t with these sorts of operations though. It’s in searching for specific patterns. Let’s start illustrating by looking at one type of pattern: a word! To illustrate these pattern searches, we’ll use another set of words, a vector of names of fruit.
Now we can try to generalize beyond the simple word case to broader patterns. These can capture more complex phenomena, which are often what we need when we are doing work with text-as-data.
To illustrate, we’ll go back to the sentences data from earlier. Now let’s look for any sentences that contain “hog”, “bog”, “log”, or “dog”.
# note that the spaces are important within the quotes below. what happens if you remove them? Why?str_subset(sentences, ' [hbd]og ')
[1] "The hog crawled under the high fence."
[2] "The kitten chased the dog down the street."
[3] "Tend the sheep while the dog wanders."
We can also negate the letters we’re using above by using ^, looking for any words that do not start with h, b, d, or l but that do end with -og. Or we can use - to look across a range of characters
length(str_subset(sentences, '[^hbdl]og'))
[1] 2
# look for anything between b and lstr_subset(sentences, ' [b-l]ot ')
[1] "The wide road shimmered in the hot sun."
[2] "Move the vat over the hot fire."
[3] "The harder he tried the less he got done."
[4] "The just claim got the right verdict."
[5] "A shower of dirt fell from the hot pipes."
[6] "The large house had hot water taps."
[7] "The lake sparkled in the red hot sun."
[8] "It takes a lot of help to finish these."
[9] "Serve the hot rum to the tired heroes."
[10] "Twist the valve and release hot steam."
[11] "Breakfast buns are fine with a hot drink."
[12] "The beetle droned in the hot June sun."
Classes and quantifiers
There are also a series of escaped characters that have special meanings. These let you match, for example, any alphanumeric character (), any space (), or any number (. These become really helpful when combined with quantifiers, which indicate the number of occurrences of the character. On this, * indicates zero or more of the character, and + indicates one more of the character.
# create some stringstutone <-c("Jenny Jenny, who can I turn to?", "867-5309")# match any number string of more than one numberstr_extract_all(tutone, "\\d+")
[[1]]
character(0)
[[2]]
[1] "867" "5309"
# match any alphanumeric string of 0 or morestr_extract_all(tutone, "\\w*")
# match any number string of more than three numbers; note the commastr_extract_all(tutone, "\\d{4,}")
[[1]]
character(0)
[[2]]
[1] "5309"
Extracting data
Where regular expressions start to get really powerful for us is in automating the extraction of information from rich digital text. Consider an example where we want to identify mentions of courts from inaugural addresses. We can leverage regular expressions to do just that:
[,1]
[1,] NA
[2,] NA
[3,] NA
[4,] NA
[5,] NA
[6,] NA
[7,] " court"
[8,] NA
[9,] NA
[10,] "judiciary "
[11,] NA
[12,] NA
[13,] "judicial "
[14,] "judiciary "
[15,] NA
[16,] "judicial "
[17,] NA
[18,] "judicial "
[19,] " Court"
[20,] NA
[21,] NA
[22,] NA
[23,] NA
[24,] " court"
[25,] NA
[26,] "judicial "
[27,] " courts"
[28,] " courts"
[29,] NA
[30,] NA
[31,] " courts"
[32,] NA
[33,] NA
[34,] " court"
[35,] " Court"
[36,] "judicial "
[37,] " court"
[38,] NA
[39,] NA
[40,] NA
[41,] NA
[42,] NA
[43,] NA
[44,] NA
[45,] NA
[46,] NA
[47,] NA
[48,] NA
[49,] NA
[50,] NA
[51,] NA
[52,] NA
[53,] NA
[54,] NA
[55,] NA
[56,] NA
[57,] NA
[58,] NA
[59,] NA
While that isn’t necessarily the most useful, consider if you were looking instead for something like the authors of each text, where the author was featured in a consistent format at the start of each text. While you could go through by hand and code each of those, it is much more straightforward to do this with regular expressions. As you start working with your corpus — and particularly if you are in any way thinking of coding something by hand from the corpus — take some time to think and to chat with me about whether it’s something we can do with regular expressions.